

This article data science blogthon.
There are various methods and platforms for managing and organizing big data. Provides a complete and trusted data repository that supports data analytics, business intelligence, and machine learning.
.png)
Let’s take a quick look at what data lakes mean in the world of technology.
What is a data lake?
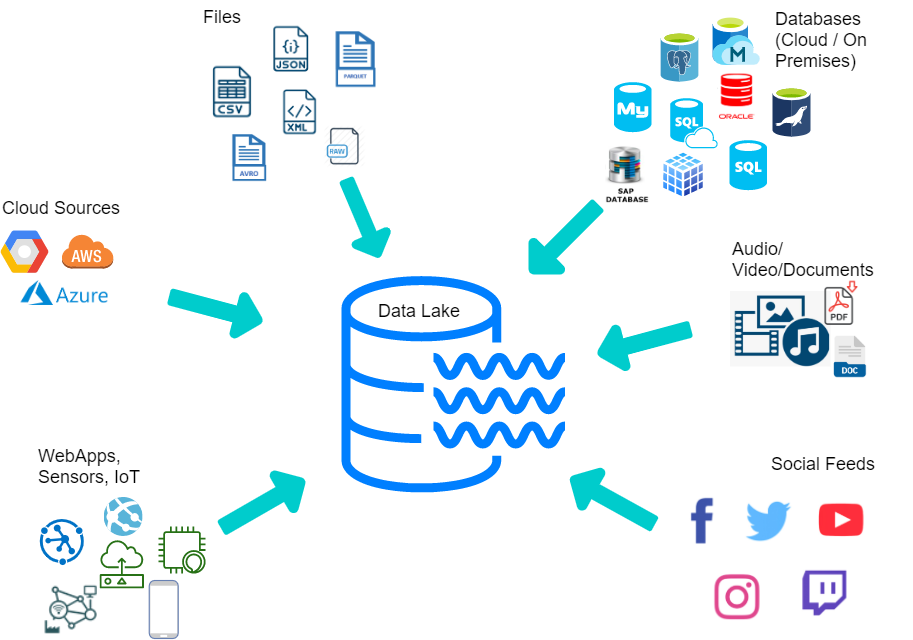
Think of a data lake as a large container that acts as a repository that can store large amounts of data in various formats, including unstructured, semi-structured, and structured data. A place where you can work with any kind of data in its native format, without hard limits on accounts or file sizes.
Data lakes can process any kind of data critical to today’s machine learning and advanced analytics, including images, videos, audio, and documents. They are becoming more and more important as people want better data exploration, especially in business and technology. In this way, businesses can spend less time searching and collecting data and more time analyzing it. Consolidating your data in one place or most of it makes your life much easier. Up-to-date data helps businesses perform advanced analytics and display up-to-date information compared to their competitors.
Amount, type and speed of data
The 3 V’s of today’s data remind us that there is no one-size-fits-all database for all your data needs. These V’s are the volume, velocity and variety of data today. The growth in data volume is enormous. With the expansion of 5G technology, it will only get bigger thanks to the wide range of possibilities it offers.
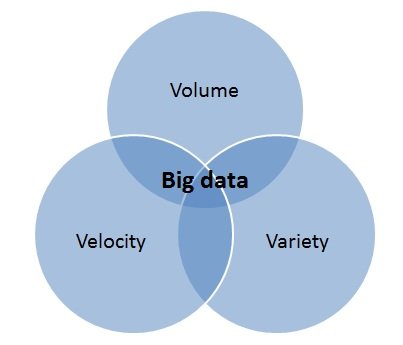
The speed at which these changes occur is so rapid that many statistics say that 90% of the data was generated after 2016. This means that it is as big and important as big data has been in the last few years. As technology makes the world more connected, it gets bigger. As for diversity, in the early 2000s, streaming was limited to audio, while broadband was primarily used for his web browsing, emailing, and downloading.
Towards the end of the decade, with the expansion of the internet and the beginning of the “smartphone age,” business priorities shifted to both audio and video streaming services, social media pervasiveness, video game streaming platforms, and more. Consumption of data in various forms.
Benefits of using a data lake
Below are some of the benefits of using a data lake as your big data management solution.
- Simple data storage – By accepting all data types, Data Lake eliminates the need for data modeling during data storage. We may do this when searching and examining data for further analysis. So they can be filtered and modeled as desired.
- Scalability – When considering scalability, it offers scalability and is relatively inexpensive compared to traditional data warehouses.
- Versatility – A data lake can store multi-structured data from a variety of sources. In a nutshell, data lakes can store logs, XML, multimedia, sensor data, binary data, social data, chat, people data, and more.
- Flexibility – Traditional schemas require data to be in a specific format. Traditional data warehousing products are schema-based, but with Data Lake you can go schemaless or create multiple Schemas can also be defined and are great for analytics.
- Multiple formats – While traditional data warehouse technologies primarily support SQL, which is suitable for simple analytics, data lakes offer a wide range of features and language support for analytics.
- Advanced Analytics – Unlike data warehouses, data lakes excel at the availability of large amounts of consistent data and leveraging deep learning algorithms. Useful for real-time decision analysis.
- Single data platform – The ability to find all your information on a single platform doesn’t need much to say. Based on your daily tasks, you can imagine the pain of navigating from one place to another to get information relevant to the one insight you care about.
- These are just a few of the main benefits, and there are other important reasons to know.
Data Lake Benefits for IoT Analytics
Put your IoT data to good use with Software AG’s Cumulocity. Cumulocity bridges the gap between streaming and historical analytics, simplifying the process for IT administrators and enabling businesses to gain new insights into operations and performance.
Simplified management of long-term data retention
Cumulocity regularly retrieves data from on-premises or edge operational data stores, transforms it into a compact format that is highly efficient for analytical queries, and puts it into the data lake’s analytical store. Cumulocity can support many devices, and for each offload, Things Cloud IoT DataHub moves each device’s alarm, event, measurement, and inventory data to the data lake.
Reduce IoT data storage costs
The analytical store can be hosted on Amazon® S3 or Microsoft® Azure® Data Lake storage of your choice. Cloud storage significantly reduces the cost of creating and managing data lakes. Cumulocity also supports file systems and Hadoop® Distributed File System (HDFS) data storage.
Scalable SQL queries for IoT data
IoT DataHub is designed to support IoT solutions consisting of any number of devices and can be scaled to manage the data each device produces. To analyze this massive amount of device data, Things Cloud IoT DataHub has provided SQL, the lingua franca of data processing, for decades. Unleash the power of SQL to quickly transform raw he IoT device data into meaningful information.
BI standard interfaces
IoT DataHub can be used for a wide range of business intelligence or analytics applications, machine learning training, or using Arrow Flight, JDBC®, ODBC, REST, and SQL.
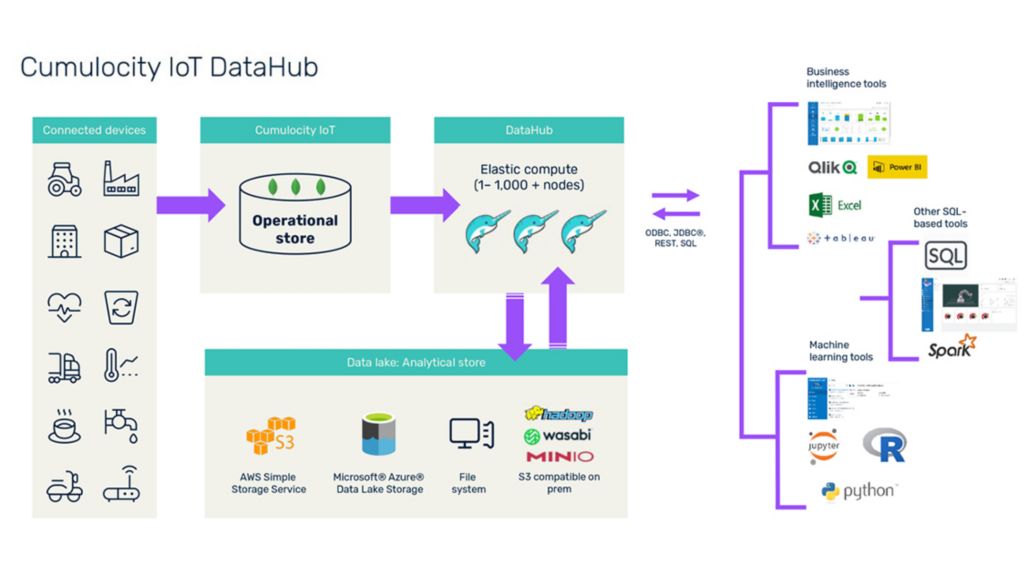
How Cumulocity data hub works?
IoT DataHub moves data from Cumulocity’s operational storage to data lakes, transforming raw IoT data into a structured, compressed format required for efficient SQL queries, reporting, and intelligence. This “offloading” process allows for inexpensive long-term archiving of device data.
What does the data look like in the data lake? This transformed tabular data is stored in Apache Parquet™ format. This gives you a convenient columnar representation of your data for analysis and efficient storage. Parquet is the de facto data format for “big data” tools, providing the independence of not only using Things Cloud, but also using tools like Apache Spark™ to process the data. Given common analytical patterns, Cumulocity IoT DataHub organizes Parquet files into a temporary folder hierarchy. An additional cleanup mechanism in the background periodically compresses small Parquet files to improve overall query performance (assuming the hard drive was previously optimized).
Once downloaded, you can use your favorite BI and data science tools to analyze data and gain insights at interactive speed. You can then extract exactly what you need and integrate that information with information from other trading systems to gain trading insights.
Combine insights from enterprise systems with IoT data
Cumulocity enables you to connect your BI queries and build tools to your IoT data, allowing you to extract all kinds of powerful business insights from your data. It provides SQL as a query interface, the lingua franca of data processing and analysis. Dremio™ is an internal engine that executes SQL queries. Dremio is highly scalable and can easily handle a wide variety of analytical queries.
With IoT DataHub, you can quickly connect to your choice of tools or applications, including:
- BI tools using JDBC or ODBC
- Data science applications using Python scripts that connect via ODBC
- Custom applications using JDBC for Java® ecosystem, ODBC for .NET, Python, etc., and REST (Cumulocity IoT) for web applications
Training machine learning models
ML is popular for gaining deeper insight into business and manufacturing processes. The more data you have, the more reliable the information from your machine learning models. Cumulocity paves the way for training complex machine learning models by making all IoT data available in a structured format suitable for analysis. Simply connect your favorite data science tools via ODBC, JDBC, or REST and start working with your data. For example, you can train a model on a valve failure condition to see what factors indicate that the valve is about to fail. We later use these insights in combination with Cumulocity live data to proactively replace valves before they break. This is the power of combining live and historical data.
Data lake and data warehouse
Data lakes tend to receive and prepare data as soon as people access it. A data warehouse, on the other hand, prepares the data very carefully beforehand before releasing it into the data warehouse.
Compared to hierarchical data warehouses, which store data in files or folders and act as a repository for structured and filtered data that has already been processed for a specific purpose, data lakes use a flat architecture. stores data in its native raw format. A format whose purpose has not yet been defined. Another benefit of an immutable data ingestion layer that stores all data received so far is valuable for auditing, data discovery, reproducibility, and correction of errors in the data stream.
Conclusion
A data lake can process any kind of data, including images, videos, audio, and documents. These are important for his Machen learning and advanced analytics cases today. They are becoming more and more important as people want better data exploration, especially in business and technology. In this way, businesses can spend less time searching and collecting data and more time analyzing it.
- The speed at which these changes occur is so rapid that many statistics say that 90% of the data was generated after 2016. This means that it is as big and important as big data has been in the last few years. As technology makes the world more connected, it gets bigger.
- Data lakes tend to receive and prepare data as soon as people access it. A data warehouse, on the other hand, prepares the data very carefully beforehand before releasing it into the data warehouse.
- IoT DataHub can be used for a wide range of business intelligence or analytics applications, machine learning training, or using Arrow Flight, JDBC®, ODBC, REST, and SQL.
- The analytical store can be hosted on Amazon® S3 or Microsoft® Azure® Data Lake storage of your choice. Cloud storage significantly reduces the cost of creating and managing data lakes. Cumulocity also supports file systems and Hadoop® Distributed File System (HDFS) data storage.
Media shown in this article are not owned by Analytics Vidhya and are used at the author’s discretion.